Creating combinations is one of the most common tasks in preprocessing techniques. Remember permutations and combinations in higher school? Yes, these are related. While there are different types of combinations, with and without hierarchies are the most used ones in practice.
Lets start simple by taking an example. Consider you have a few categorical variables/Dimensions (D1, D2, D3) and continues variable/Measures (M1), (M2). If you were asked, how many ways can D1, D2, D3 be arranged? You will take a simple factorial of 3. That is 3! = 6 ways. Following are the different possible sequences:
- D1, D2, D3
- D1, D3, D2
- D2, D3, D1
- D2, D1, D3
- D3, D1, D2
- D3, D2, D1
Now these are sequences within the Dimensions, and also called as hierarchies. The values (records) under these Dimensions can be combined in different sequences and be called as combinations.
We now know what are hierarchies and combinations. Lets create combinations among the dimensions by picking a sample dataset from supply chain management.
Here is a sample of the first 10 records. As we can observe, for a single date, we have multiple records in a transactional nature.
| D1 | D2 | D3 | Date | M1 | M2 |
| Pacific Asia | Consumer | Southeast Asia | 2018-01-31T00:00 | 327.75 | 13.11 |
| Pacific Asia | Consumer | South Asia | 2018-01-13T00:00 | 327.75 | 16.39 |
| Pacific Asia | Consumer | South Asia | 2018-01-13T00:00 | 327.75 | 18.03 |
| Pacific Asia | Home Office | Oceania | 2018-01-13T00:00 | 327.75 | 22.94 |
| Pacific Asia | Corporate | Oceania | 2018-01-13T00:00 | 327.75 | 29.5 |
| Pacific Asia | Consumer | Oceania | 2018-01-13T00:00 | 327.75 | 32.78 |
| Pacific Asia | Home Office | Eastern Asia | 2018-01-13T00:00 | 327.75 | 39.33 |
| Pacific Asia | Corporate | Eastern Asia | 2018-01-13T00:00 | 327.75 | 42.61 |
| Pacific Asia | Corporate | Eastern Asia | 2018-01-13T00:00 | 327.75 | 49.16 |
If we were to do get all the possible combinations (without any defined hierarchies) between D1, D2, D3, we will have to consider all the 6 (3!) hierarchies between the dimensions.
To achieve this, we have a defined function “cube” in pyspark. The input parameters to cube will be all the dimensions on which you would like to build the combinations. Following is the code structure for the above dataset that I have used.
#Importing Required packages
import pyspark
from pyspark.sql import SparkSession, functions as F, types as T, Window as W
#Creating a sparksession and initializing a sparkcontext of it.
spark_session = SparkSession.builder \
.appName("Learn_Cube_Rollup") \
.getOrCreate()
sc = spark_session.sparkContext
sqlCtx = pyspark.SQLContext(sc)
#Reading a csv file into spark dataframe
dataframe_spark = spark_session.read.format("csv")\
.option("header", "true")\
.load("../input/sample-sc")
#Applying cube function to the dimension columns along with Date
#Aggregating the measure values for a particular combination values
dataframe_spark = dataframe_spark.select(["D1","D2","D3", "Date", "M1", "M2"])\
.cube(["D1","D2","D3", "Date"])\
.agg(*((F.sum(col)).alias('{}'.format(col)) for col in ["M1", "M2"]))\
.sort(["D1","D2","D3", "Date", "M1", "M2"]).cache()
#Filtering out combinations with null Date columns
dataframe_spark = dataframe_spark.filter(
~reduce(lambda x, y: x & y, [dataframe_spark[c].isNull() for c in ["Date"]]))\
.show()

Now, what if you wanted combinations for a specific hierarchy? For instance, of the 6 hierarchies, what if you wanted all the combinations of D2,D3,D1? You would compute a cube function and remove all the combinations corresponding to the remaining 5 hierarchies? Its cumbersome, memory and time consuming, and simply not intelligent.
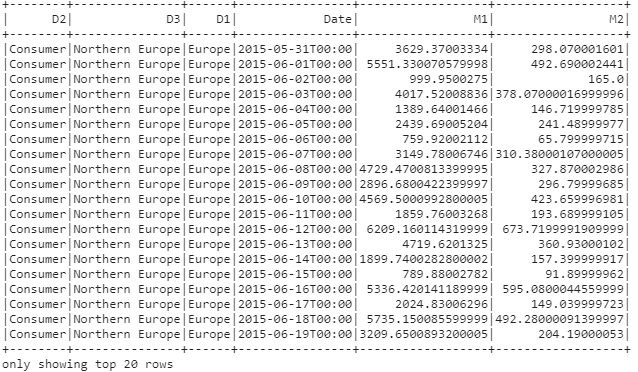
Instead, pyspark offers a function Rollup that is for this specific use case. Consider the above dataset. If we perform a rollup for the hierarchy D2,D3,D1, the rollup function strictly follows the same hierarchy. i.e, D2 -> D3 -> D1. Below is a code walk though of it:
dataframe_spark = dataframe_spark.select(["D1","D2","D3", "Date", "M1", "M2"])\
.rollup(["D2","D3","D1", "Date"])\
.agg(*((F.sum(col)).alias('{}'.format(col)) for col in ["M1", "M2"]))\
.sort(["D1","D2","D3", "Date", "M1", "M2"]).cache()
dataframe_spark = dataframe_spark.filter(
~reduce(lambda x, y: x & y, [dataframe_spark[c].isNull() for c in ["Date"]]))\
.show()
The dataframe after rollup looks as below: