
Introduction to NLP based prediction model to predict Defaulters
Part II
This is the second part of the Case Study, the first part can be accessed here : Part I
Do you remember filling in details while applying for a loan? In which, a blank box ‘description’ is provided to fill in the reason for loan. To my ignorance, I always believed that information was only a reference for the loan officer. What if that information was also used in the back end to decide if I am eligible for a loan?

As you remember in the Part-I, we are working for a Bank that lends loans to individuals. In this section, we will try understanding if we can decide loan sanctions based on the reasons that they mention while filling in the form.
Lets dive into the dataset. Following are a few reasons that we see from different applicants:
- Borrower added on 12/22/11 > I need to upgrade my business technologies.
- Borrower added on 12/22/11 > I plan to use this money to finance the motorcycle i am looking at. I plan to have it paid off as soon as possible/when i sell my old bike. I only need this money because the deal im looking at is to good to pass up.
- Borrower added on 12/19/11 > I intend to pay this debt off within half the time allotted.Home-brewer investing in equipment, hopefully someday a brewpub owner with delicious beers to sell and locally grown produced meat and vegetables.So, this is my start, and thank you for lending! One day I will repay the favor and lend back
Its very interesting to note that people take loans for wide variety of reasons. Few explain and a few just ask. However for most often times, we see people promising to pay it back.
So lets get started to analyze each descriptions using text analytics/ NLP methods. We can see from the samples that the text has few redundant, repetitive words. We also see some dates, numbers in the text. Hence, we need to clean it before its further analyzed.
Step-1:
Reading the csv excel file into a pandas dataframe and retaining only unique ID, Description columns/ fields. Since we are trying to predict if the applicant will default or not, we will have to retain the ‘loan status’ field as well. (When we have a labeled data and specific target variable, we call it supervised learning)
#Freshly reading the data into 'data' dataframe
data = pd.read_csv("/content/drive/My Drive/Projects/Dipyaman Project/fullacc.csv")
data_nlp = data[['id', 'loan_status', 'desc']].copy() #selecting only required fields for NLP Analysis
data_nlp.dropna(subset=['desc'], inplace=True) #Dropping all unavailable 'desc' records
data_nlp # Please observe the uncleaned 'desc' field.
Lets have a quick check on how the selected dataframe looks like. As we can see, all the entries under ‘desc’ field has repetitive words. Let’s clean them up using regular expressions.
id loan_status desc
0 1077501 0 Borrower added on 12/22/11 > I need to upgra...
1 1077430 1 Borrower added on 12/22/11 > I plan to use t...
3 1076863 0 Borrower added on 12/21/11 > to pay for prop...
4 1075358 0 Borrower added on 12/21/11 > I plan on combi...
6 1069639 0 Borrower added on 12/18/11 > I am planning o...
... ... ... ...
230710 1062337 0 Borrower added on 12/11/11 > pay off credit ...
230711 1062400 0 Borrower added on 12/08/11 > I will be payin...
230714 1058722 1 Borrower added on 12/06/11 > need to pay off...
230715 1058291 0 Borrower added on 12/06/11 > Want to close d...
316501 401243 0 To whom it may concern, Hello, my name is ...
110721 rows × 3 columns
k=0
desc_list=[]
for line in data_nlp.desc:
text = re.sub('<.*?>', '',line) #This expression removes the <br> which is found at the end of every sentence
desc_list.append(re.sub('Borrower added on \d{2}/\d{2}/\d{2} >', '', text)) # This removes the date/year in every sentence
k=k+1
data_nlp['desc_cleaned'] = desc_list
Now that we have cleaned the ‘description’ field and renamed it to ‘desc_cleaned’, this is good to be analysed.
But we are still a step away from analyzing it. If we look closely, there are a lot of conjunction words/ most frequently used words in English. They do not provide a great value to understanding ‘what unique constructions do each applicant has?’. We treat such words by ‘stopword’ removal techniques. Since, the description column is a sentence, we need to first break it. An additional step that makes sentences even better understood to a model is by Lemmatizing each word.
Step-2
Lets Tokenize, Lemmatize and then remove the stopwords. I have chosen NLTK package for simplicity.
from gensim.utils import tokenize
from gensim.parsing.preprocessing import remove_stopwords
import nltk
from nltk.corpus import stopwords
nltk.download('stopwords')
nltk.download('punkt')
from nltk.corpus import stopwords
from nltk.tokenize import word_tokenize
stop_words = set(stopwords.words('english'))
from nltk.stem import WordNetLemmatizer
nltk.download('wordnet')
## Tokenising, Lemmatising and then removing the stop words.
k = 0
filtered_sentence = []
final_sentence=[]
lemmatizer = WordNetLemmatizer()
stop_words = set(stopwords.words('english'))
for line in data_nlp.desc_cleaned:
line=lemmatizer.lemmatize(line)
word_tokens = word_tokenize(line)
filtered_sentence = []
for w in word_tokens:
if w.isalnum(): #considering only Alpha-numberic charachters
if w not in stop_words:
filtered_sentence.append(w)
final_sentence.append(' '.join(filtered_sentence))
data_nlp['desc_cleaned'] = final_sentence
When we check the ‘desc_cleaned’ column, we find a lot of repetitive words. Lets go ahead and try removing the most common words. The main idea behind removing such words is to ‘keep unique differentiating words that describes an applicant. Further, the model performs better if we feed in a wide variety of data!’.
## Checking the most frequent and least occouring words and removing them.
temp=[]
for line in data_nlp.desc_cleaned:
temp.append(''.join(line))
#BOW.append(' '.join(line))
#BOW=''.join(BOW)
temp=str(temp).split()
k=0
BOW=[]
while k<len(temp):
if temp[k].isalnum():
BOW.append(''.join(temp[k]))
k=k+1
from collections import Counter
diction = Counter(BOW).most_common(100)
import matplotlib.pylab as plt
lists = sorted(diction) # sorted by key, return a list of tuples
plt.subplots(figsize=(20,12))
x, y = zip(*diction) # unpack a list of pairs into two tuples
plt.xticks(rotation=90)
plt.plot(x, y)
plt.show()
print(Counter(BOW).most_common(40))
### Based on the below graph, we will be removing the top repeating words till 'good'
remove_list=[]
i=0
remove_dict= Counter(BOW).most_common(39)
while i < 39:
remove_list.append(remove_dict[i][0])
i=i+1
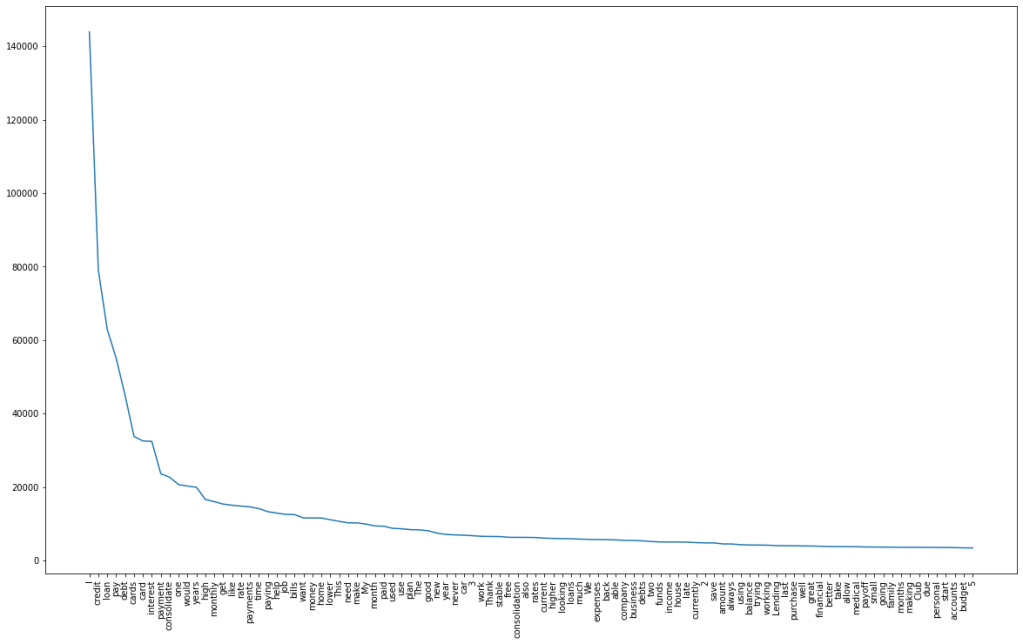
Following are the list of words that needs to be removed. I have considered removal of Top-n words idea based on its meaning. I have chosen the list till the word ‘good’
### Removing the most occouring words from remove_list and rebuilding the 'desc_cleaned' column:
filtered_sentence = []
final_sentence=[]
for line in data_nlp.desc_cleaned:
word_tokens = word_tokenize(line)
filtered_sentence = []
for w in word_tokens:
if w.isalnum():
if w not in remove_list:
filtered_sentence.append(w)
final_sentence.append(' '.join(filtered_sentence))
data_nlp['desc_cleaned'] = final_sentence
data_nlp
id loan_status desc desc_cleaned
0 1077501 0 Borrower added on 12/22/11 > I need to upgra... upgrade business technologies
1 1077430 1 Borrower added on 12/22/11 > I plan to use t... finance motorcycle looking soon sell old bike ...
3 1076863 0 Borrower added on 12/21/11 > to pay for prop... property tax borrow friend back central replac...
4 1075358 0 Borrower added on 12/21/11 > I plan on combi... combining three large together freeing extra t...
6 1069639 0 Borrower added on 12/18/11 > I am planning o... planning using funds two retail rates well maj...
... ... ... ... ...
230710 1062337 0 Borrower added on 12/11/11 > pay off credit ... faster never missed late secure
230711 1062400 0 Borrower added on 12/08/11 > I will be payin... three balances business several always debit a...
230714 1058722 1 Borrower added on 12/06/11 > need to pay off... truck note expenses happy offer personal loans
230715 1058291 0 Borrower added on 12/06/11 > Want to close d... Want close way alot easier magagement
316501 401243 0 To whom it may concern, Hello, my name is ... To may concern Hello name David McLean request...
110721 rows × 4 columnsStep-3:
Now the ‘desc_cleaned’ has relatively cleaner data and is good to be fed into a model. As we know, for a computer to process any information it has to be in a form that it can understand. Here, we are creating a model utilizing an algorithm that is fed with English words! How will the model understands such input? Hence, we will have to first convert them in a numbers form using ‘Embedding’ techniques. Here, I am taking two simple techniques : CountVectorizer and TFIDF.
Lets explore Naive Bayes with CountVectorized embeddings
Naive Bayes – CountVectorizer
from sklearn.feature_extraction.text import CountVectorizer
from sklearn.model_selection import train_test_split
from sklearn import metrics #Import scikit-learn metrics module for accuracy calculation
cv = CountVectorizer(lowercase=True,stop_words='english',ngram_range = (1,1))
text_counts= cv.fit_transform(data_nlp['desc_cleaned'])
X_train, X_test, y_train, y_test = train_test_split(
text_counts, data_nlp['loan_status'], test_size=0.3, random_state=45)
from sklearn.naive_bayes import MultinomialNB
# Model Generation Using Multinomial Naive Bayes
clf = MultinomialNB().fit(X_train, y_train)
predicted= clf.predict(X_test)
print("MultinomialNB Accuracy:",metrics.accuracy_score(y_test, predicted))
MultinomialNB Accuracy: 0.825029Naive Bayes – TFIDF
from sklearn.feature_extraction.text import TfidfVectorizer
tf=TfidfVectorizer()
text_tf= tf.fit_transform(data_nlp['desc_cleaned'])
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(
text_tf, data_nlp['loan_status'], test_size=0.2, random_state=45)
from sklearn.naive_bayes import MultinomialNB
#Import scikit-learn metrics module for accuracy calculation
from sklearn import metrics
# Model Generation Using Multinomial Naive Bayes
clf = MultinomialNB().fit(X_train, y_train)
predicted= clf.predict(X_test)
print("MultinomialNB Accuracy:",metrics.accuracy_score(y_test, predicted))
MultinomialNB Accuracy: 0.84064Single Layered ANN
from sklearn.feature_extraction.text import TfidfVectorizertf=TfidfVectorizer()text_tf= tf.fit_transform(data_nlp['desc_cleaned'])
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(
text_tf, data_nlp['loan_status'], test_size=0.2, random_state=45)
from keras.models import Sequential
from keras import layers
input_dim = X_train.shape[1]
model = Sequential()
model.add(Dense(input_dim=input_dim, activation="relu", kernel_initializer="uniform", units=15))
model.add(Dense(activation = 'sigmoid', kernel_initializer = "uniform", units = 1))
model.compile(optimizer = 'adam', loss = 'binary_crossentropy', metrics = ['accuracy'])
model.fit(X_train, y_train, batch_size = 10, nb_epoch = 100)
Accuracy : 0.9420This is a very simple project application of NLP where we are predicting if an applicant will default based on the reason of application. There is a lot of scope to further play around this idea. You can access my code here and feel free to explore further.

One thought on “Minimizing Loan Evasions for a Bank – 2”